
本文只记录项目思路、部署流程和实验结果,不公开核心源码、模型权重、bitstream、完整数据集和板卡登录信息。涉及 HLS 内核、权重导出和板端推理脚本的实现细节只做工程层面的说明。
这次做的是一个光瓣识别项目:输入一张光斑/光瓣图像,模型判断它属于 10 个类别中的哪一类。普通的 PC 端训练和推理并不难,真正花时间的是把模型放到 FPGA 板子上,让它在 PYNQ-Z2 上完成一次可以复现的推理闭环。
所以这篇文章不重点讲模型结构怎么设计,也不展开 HLS 内核代码,而是记录一条更工程化的主线:
在 PC 端完成训练和定点参考验证。
用 Vitis HLS 生成可综合的硬件 IP。
用 Vivado 生成 PYNQ-Z2 可加载的 bitstream 和 hwh。
把 bitstream、权重和验证图片放到板端。
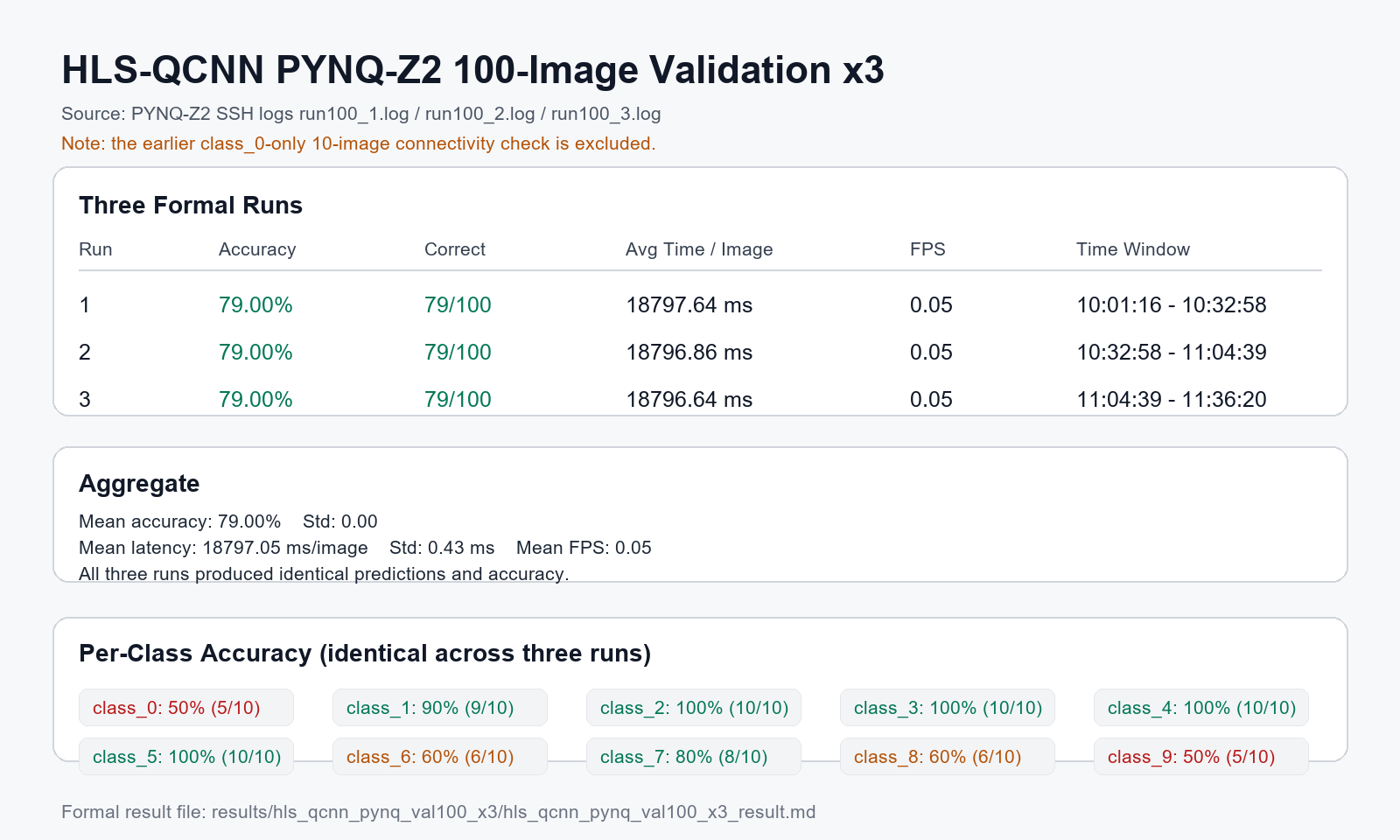
在 PYNQ-Z2 上跑完 100 张验证图,并重复 3 次确认结果稳定。
最后的结果是:PYNQ-Z2 板端连续 3 次跑完 100 张验证图,每次准确率都是 79.00%。这说明模型已经完成了从 PC 训练到 FPGA 上板推理的闭环。当前版本平均单张耗时约 18.8 s,速度不快,但它的目标本来就是先验证部署流程和结果一致性,不是追求最高吞吐。
项目目标
这个项目可以分成两个目标。
第一个目标是识别:用神经网络对光瓣图像做 10 分类。数据集共 500 张图片,按 400 张训练、100 张验证划分,每个类别在验证集中有 10 张图片。
第二个目标是部署:让一个轻量化的定点模型真正跑在 PYNQ-Z2 的 FPGA 逻辑上,而不是只停留在 PC 端 Python 推理。对于这个目标,判断成功的标准不是 FPS 有多高,而是下面几件事是否闭合:
PC 端定点参考结果可用。
HLS C 仿真输出和参考结果一致。
Vivado 能生成匹配的
.bit和.hwh。PYNQ-Z2 能加载 overlay。
板端能读取权重和图片,完成单张与批量推理。
100 张验证集可以完整跑完,并且结果可重复。
整体路线
这次采用的是 HLS-QCNN 上板路线。PC 端负责训练、定点参考验证、HLS/Vivado 构建;PYNQ-Z2 板端只负责加载硬件文件并运行推理脚本。
可以把流程理解成这样:
数据集
-> PC 端训练/验证
-> 定点参考模型
-> HLS 所需权重和测试 artifact
-> Vitis HLS 生成 HLS IP
-> Vivado 生成 bit/hwh
-> 上传到 PYNQ-Z2
-> 板端单图测试
-> 100 张验证集 x 3 次重复实验
这条路线的关键点是:先在 PC 端把定点参考跑通,再进入 HLS/Vivado。否则如果一上来就排查板端问题,会很难判断错误来自模型、量化、权重导出、HLS 内核还是 PYNQ 运行环境。
环境配置
本次使用的硬件和工具链如下:
这里有一个很实际的坑:Xilinx 2020.2 工具链对中文路径并不友好。项目本身可以放在中文目录下管理,但运行 HLS/Vivado 时,建议复制到纯英文路径,例如:
C:\hls_light_petal
这样可以减少一些莫名其妙的路径解析问题。尤其是自动化脚本、Tcl、临时工程目录混在一起时,路径问题会非常浪费时间。
项目效果
下面是几张本地识别效果展示图,用来直观看一下这个任务的数据形态和输出效果。

PC 端参考结果
在正式上板前,我先看了 PC 端模型和 HLS-QCNN 定点参考的表现。
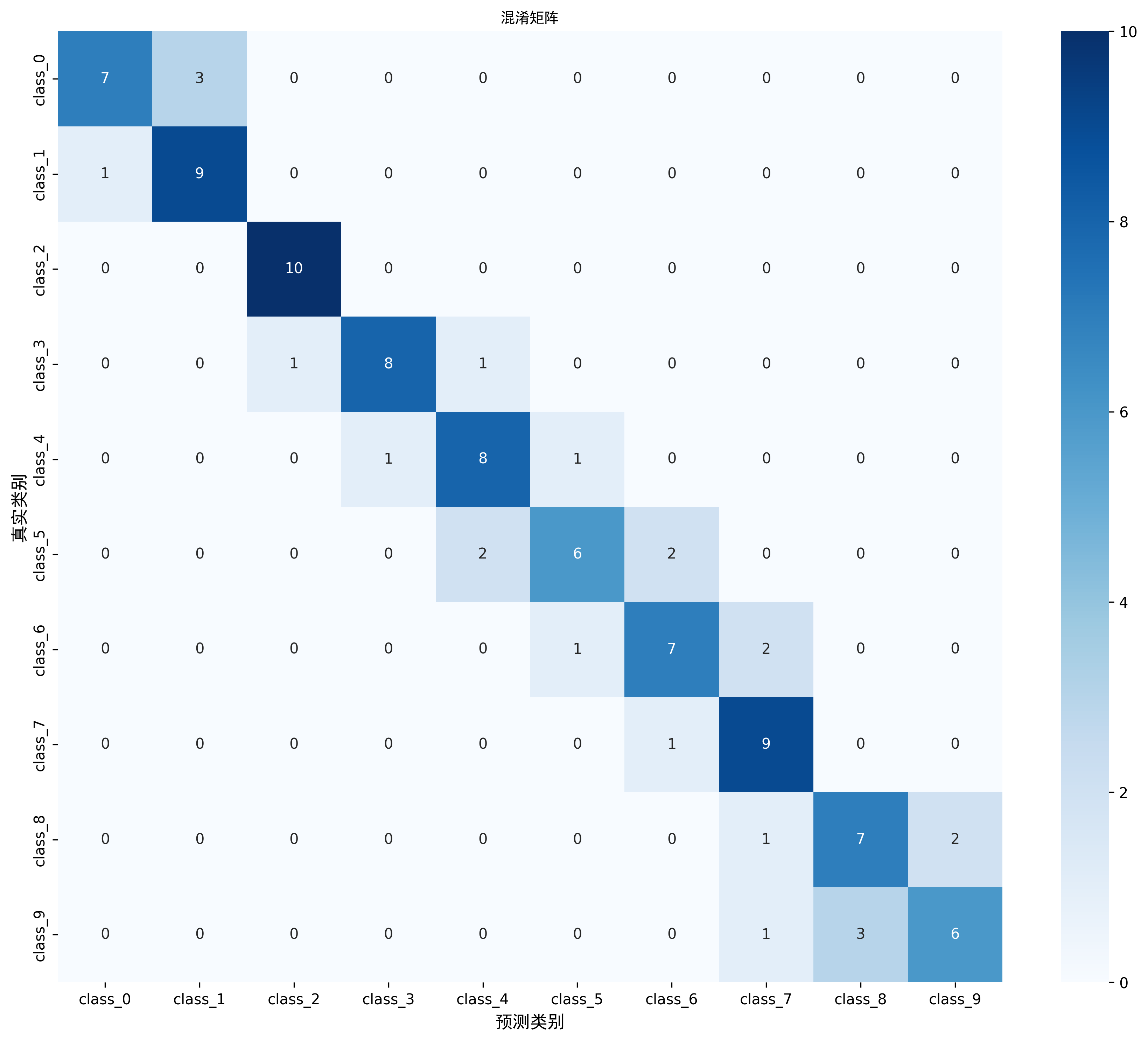
PC 端 MobileNetV2 在 100 张验证集上的结果如下,混淆矩阵可以帮助判断哪些类别更容易混淆。

PC 端 MobileNetV2 在 100 张验证集上的结果是:
HLS-QCNN 有多个检查点,其中瘦身版本在 PC 端定点参考中的结果较好:
不过板端最终结果不一定和 PC 端浮点或定点测试完全一样,因为上板后还会受到权重量化、数据布局、定点缩放、寄存器传参、DDR 访问和图像预处理一致性的影响。因此我更关注的是:板端结果是否能稳定跑完,并且保持在可接受的准确率范围内。
HLS 与 Vivado 构建
HLS-QCNN 的板端版本使用定点权重和定点激活。当前实现采用 DDR 存放权重和中间特征图,PL 端执行卷积计算。这个版本优先保证正确性和可部署性,所以没有使用更激进的并行化设计。
构建过程大致分三步。
第一步,生成 HLS 所需的参数、权重和测试输入。这里会把训练得到的模型转换成 HLS 工程可以使用的 artifact,并准备一张单图用于 C 仿真比对。
python hls_cnn\generate_hls_qcnn_artifacts.py
第二步,运行 Vitis HLS,完成 C 仿真、综合和 IP 导出。
hls_cnn\run_hls_qcnn.bat
如果 C 仿真阶段输出的类别、logits 或错误数不符合预期,就不要继续跑 Vivado。先把定点参考、权重导出和 HLS testbench 对齐。
第三步,运行 Vivado,生成 PYNQ-Z2 可以加载的 .bit 和 .hwh。
hls_cnn\run_vivado_qcnn.bat
本次 Vivado 设计大致是:
Zynq PS + HLS-QCNN IP
HLS m_axi_gmem -> PS S_AXI_HP0
HLS s_axi_control -> PS M_AXI_GP0
当前版本没有使用 AXI DMA。输入图像、权重、中间 buffer 和输出 logits 都由 PYNQ 在 DDR 中分配,HLS IP 通过 AXI Master 访问。
构建完成后,关键产物是:
hls_qcnn.bit
hls_qcnn.hwh
hls_qcnn_weights_flat.npy
hls_qcnn_inference.py
其中 .bit 和 .hwh 必须来自同一次 Vivado 构建,不能混用。很多 overlay 加载失败或寄存器映射异常,最后都能追到这两个文件不匹配。
资源使用情况
HLS 综合阶段的资源估算大致如下:
Vivado 实现后的资源记录如下:
从资源上看,PYNQ-Z2 是可以放下这个设计的。真正的问题不是资源不够,而是当前实现的计算并行度和 DDR 访问方式还比较保守,所以速度比较慢。
上传到 PYNQ-Z2
板端只需要运行推理,不需要安装 Vivado 或 Vitis HLS。建议在板端建立一个独立目录,例如:
mkdir -p ~/hls_qcnn_test
然后把下面这些文件上传到这个目录:
hls_qcnn.bit
hls_qcnn.hwh
hls_qcnn_weights_flat.npy
hls_qcnn_inference.py
test_images/
验证图片目录建议保持这种结构:
test_images/
class_0/
class_1/
...
class_9/
正式验证时,每类 10 张,共 100 张。上传完成后可以在板端检查图片数量:
find test_images -type f | wc -l
期望输出是:
100
为了避免泄露板卡地址和登录信息,下面命令里的用户、IP 和路径都用占位符表示:
scp hls_qcnn.bit <board-user>@<board-ip>:~/hls_qcnn_test/
scp hls_qcnn.hwh <board-user>@<board-ip>:~/hls_qcnn_test/
scp hls_qcnn_weights_flat.npy <board-user>@<board-ip>:~/hls_qcnn_test/
scp hls_qcnn_inference.py <board-user>@<board-ip>:~/hls_qcnn_test/
scp -r test_images <board-user>@<board-ip>:~/hls_qcnn_test/
单图测试
批量测试之前,先跑一张图。单图测试的意义不是看准确率,而是确认 overlay 能加载、权重能读取、图像预处理流程没错、寄存器传参和输出读取正常。
板端运行时需要带上 bitstream、权重和图片路径:
cd ~/hls_qcnn_test
sudo env XILINX_XRT=/usr PYTHONPATH=/home/<board-user> \
python3 hls_qcnn_inference.py \
--bitstream hls_qcnn.bit \
--weights hls_qcnn_weights_flat.npy \
--image test_images/class_0/10.jpg
如果输出中能看到预测类别、logits 和单图耗时,说明基础链路已经连通。
这里最常见的错误有几个:
直接运行脚本但忘记传
--bitstream和--weights。.bit和.hwh不是同一组。权重文件不是当前 bitstream 对应的版本。
PYTHONPATH或XILINX_XRT环境变量没有设置好。测试图片的预处理方式和训练/定点参考阶段不一致。
100 张验证集测试
单图跑通后,再跑完整 100 张验证集:
cd ~/hls_qcnn_test
sudo env XILINX_XRT=/usr PYTHONPATH=/home/<board-user> \
python3 hls_qcnn_inference.py \
--bitstream hls_qcnn.bit \
--weights hls_qcnn_weights_flat.npy \
--test_dir test_images
当前版本一张图大约 18.8 秒,100 张图接近半小时。因此正式实验时我没有只跑一次,而是连续跑了 3 次,并保存每次日志。
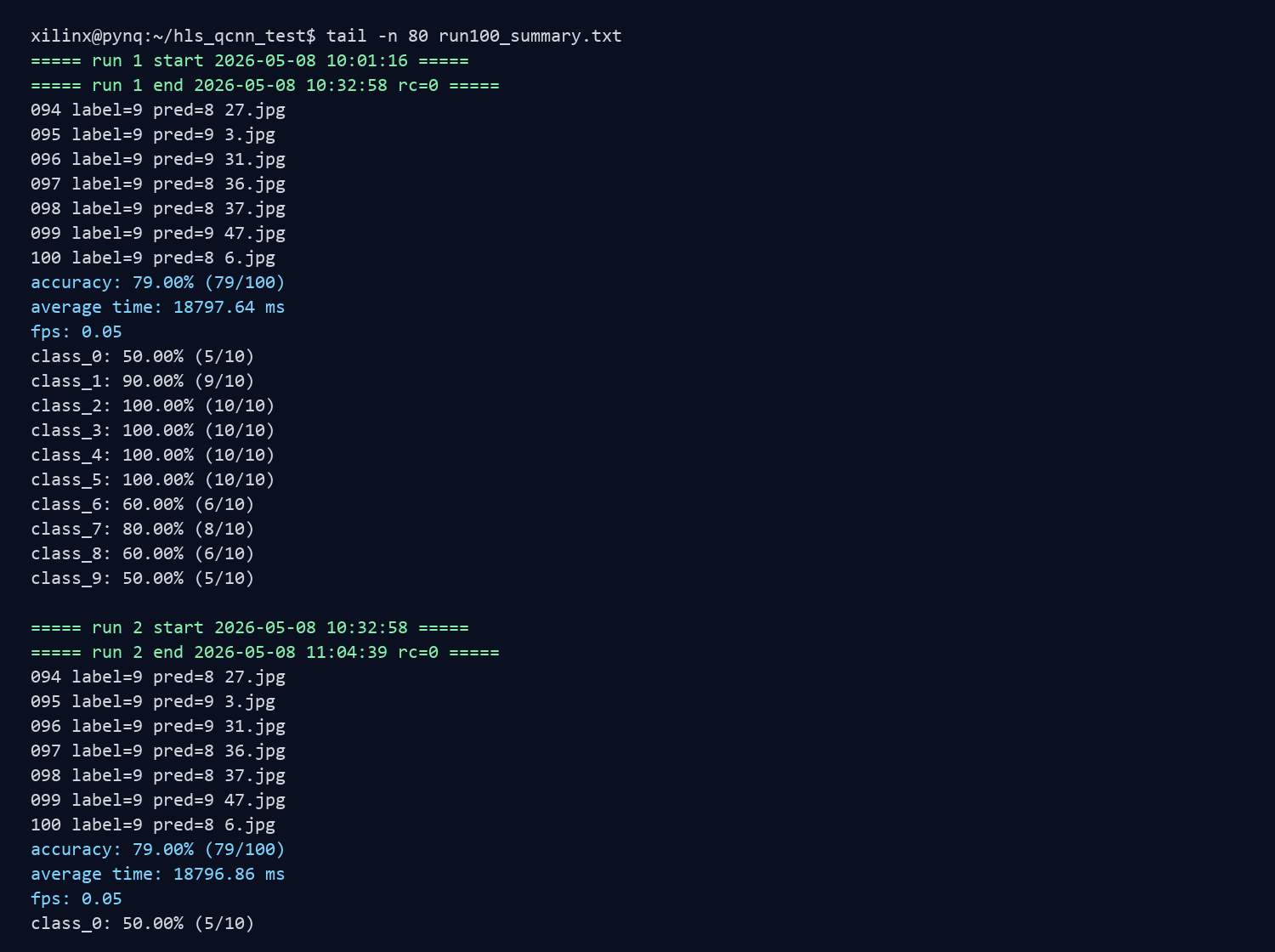
板端实验结果
正式板端实验使用的是 100 张验证图像,10 个类别,每类 10 张。早期只跑 class_0 的 10 张测试只作为连通性检查,不计入正式结果。
三次重复实验结果如下:
汇总结果:
每类准确率如下,三次重复实验结果一致:
这个结果说明两件事。
第一,部署闭环是成功的。模型不是只在 PC 上跑通,而是完成了 HLS IP、Vivado bitstream、PYNQ overlay 加载和板端批量推理。
第二,当前版本还不是性能优化版本。平均 18.8 s/image 的延迟非常高,只适合作为 correctness-first 的基线。后续如果要做实时识别,必须继续优化硬件结构。
结果截图
这里建议放三张截图:
三次重复实验汇总截图。
板端终端日志截图。
下面两张图分别对应三次重复实验汇总和板端终端日志,避免使用早期导出时出现中文乱码的截图。
踩坑记录
这次部署中比较值得记录的坑有几个。
第一,HLS/Vivado 尽量使用英文路径。中文路径在 Python 里通常没问题,但 Xilinx 工具链、Tcl 脚本和临时工程混在一起时,容易出现不稳定问题。
第二,先跑 PC 端定点参考,再跑 HLS。定点参考如果没有过,板端调试只会更混乱。
第三,.bit、.hwh、权重文件和推理脚本要作为一组管理。只替换其中一个文件,很容易出现 overlay 能加载但结果不对的情况。
第四,PYNQ 运行脚本时要明确传参数。不要直接运行推理脚本,至少要传入 bitstream 和权重文件。
第五,正式结果要和连通性测试分开。单图测试或某一类的 10 张图片只能证明链路能跑,不能代表完整模型效果。最终记录应该以完整验证集为准。
后续优化方向
当前版本证明了“能上板、能推理、能复现”。如果继续往性能方向做,可以考虑下面几个方向:
使用 tile 或 line buffer,减少中间特征图反复读写 DDR。
提高 MAC 并行度,让 PL 端真正发挥并行计算优势。
对权重做片上缓存或分层缓存。
在精度允许的前提下降低输入尺寸或通道数。
重新设计数据搬运方式,引入 DMA 或更合理的流水结构。
继续比较 PC 端定点参考、HLS C 仿真和板端输出,保证优化过程中不破坏结果一致性。
总结
这次 PYNQ-Z2 光瓣识别部署完成了一条完整链路:从 PC 端训练和定点验证,到 Vitis HLS 生成 IP,再到 Vivado 生成 bitstream,最后在 PYNQ-Z2 上跑完 100 张验证图并重复 3 次。
最终板端三次实验均为 79/100,平均准确率 79.00%,说明部署结果是稳定的。虽然当前平均单图耗时约 18.8 s,距离实时推理还有很大差距,但这个版本已经给后续优化提供了一个可复现的硬件部署基线。
对我来说,这次最有价值的不是某一个单独指标,而是把“模型训练”推进到了“FPGA 上实际运行”。后续优化速度时,也可以基于这条已经跑通的链路逐步改,而不是从一堆不确定问题里重新开始。