

定义掩码区域
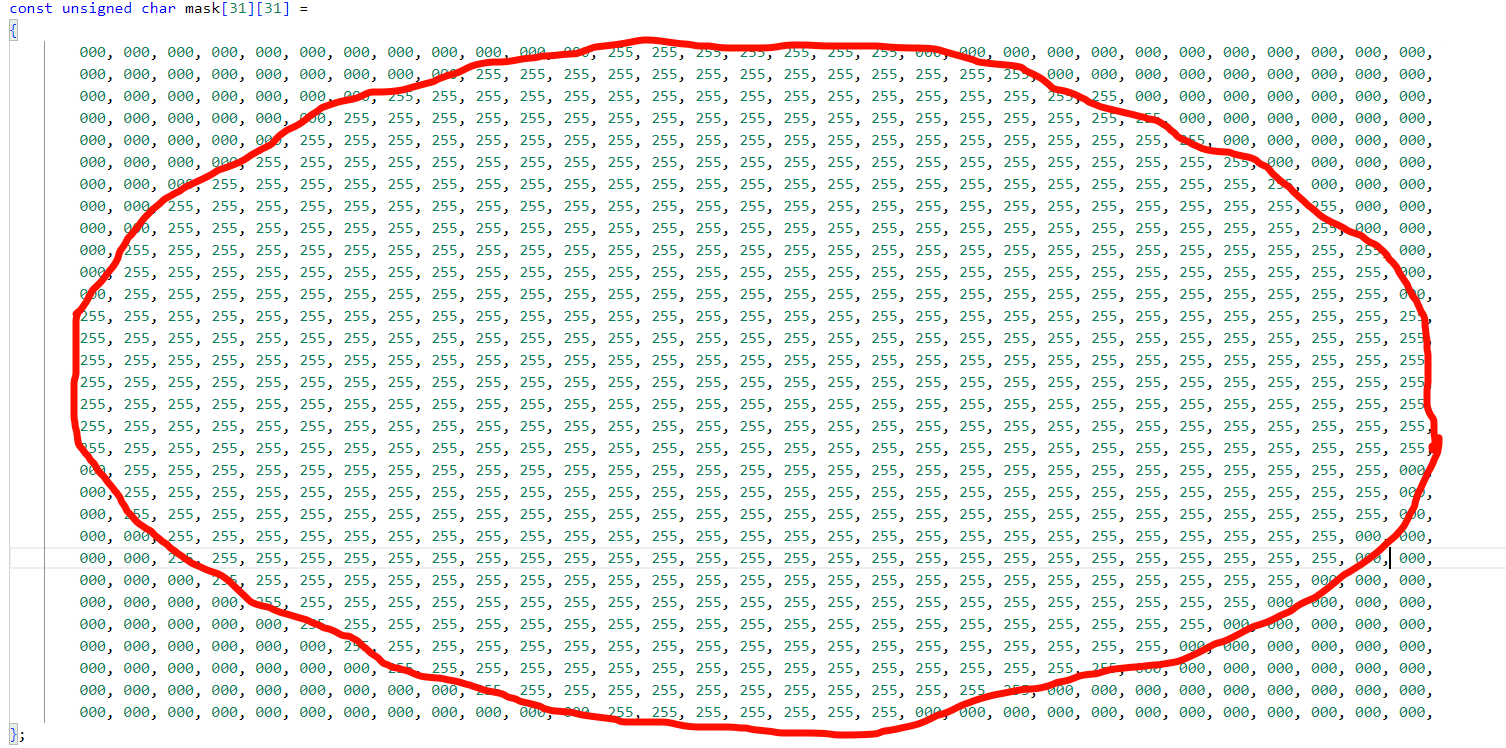
31x31 像素大小,中间区域为 255(有效),边缘区域为 0(无效),整体呈 “对称的类圆形有效区域”。
我这边粗略的划了一下,实际上是更接近圆的,因为字符间距的问题,我这边画成椭圆了。
/
具体作用有三点:
1.限定“有效像素范围",避免边缘越界
FAST 检测和 BRIEF 描述子提取都需要以候选角点为中心,取周围一定范围的像素进行计算(如 FAST 需比较中心像素与周围像素的灰度)。31x31是一个固定的“窗口大小",掩码中“0"的区域表示“该位置像素无效(如图像边缘无像素)“,“255”表示“该位置像素有效(可参与计算)“,本质是提前定义窗口内哪些像素需要被读取,避免代码运行时访问图像外的.无效内存(越界错误)。
/
2.适配FAST的“邻域灰度比较逻辑”
标准FAST算法(如FAST-9/10/11/12)是通过比较“中心像素”与“周围16个离散像素”的灰度差来判断是否为角点(若连续N个像素灰度差超过阈值,则为角点)。
ORB-SLAM3中31x31的掩码是对这一逻辑的扩展:更大的邻域(31x31)可覆盖更多像素,既能提高角点检测的鲁棒性(减少噪声干扰),也能适配图像金字塔的“尺度不变性”需求(不同金字塔层对应不同尺度,大尺度层需要更大的窗口才能覆盖同等物理范围的像素)。
/
3.保证“旋转不变性”的计算一致性
ORB 的核心优势之一是“旋转不变性"——会先计算FAST角点的“主方向”(基于周围像素的灰度梯度),再将描述子窗口旋转到主方向。
31x31掩码的“对称类圆形结构”是关键:无论窗口如何旋转,对称的有效区域能保证“旋转后读取的像素分布与旋转前一致",不会因旋转导致有效像素范围偏移,从而确保描述子的旋转不变性(若掩码是矩形,旋转后边缘像素会偏移,破坏一致性)。
/
/
Moments函数
作用:函数从输入流读取打包的图像像素数据,通过一个 31x31 的滑动窗口缓存(src_buf)实时缓存像素,结合预设的 31x31 掩码(mask)筛选有效像素,计算窗口区域的一阶矩(用于特征方向判断、重心定位等),最终将计算结果打包成 64 位数据通过输出流发送。
/
源代码:
void Moments(hls::stream<ap_uint<264> > & datapackStreamIn,
hls::stream<ap_uint<64> > & momentPackStream,uint16_t img_height, uint16_t img_width )
{
#pragma HLS ARRAY_PARTITION variable=mask complete dim=1
#pragma HLS ARRAY_PARTITION variable=mask complete dim=2
unsigned char src_buf[31][31];
#pragma HLS ARRAY_PARTITION variable=src_buf complete dim=1
#pragma HLS ARRAY_PARTITION variable=src_buf complete dim=2
for(int i=0;i<img_height*(img_width+15);i++)
{
ap_uint<264> inPack = datapackStreamIn.read();
ap_uint<248> temp = inPack.range(247,0);
unsigned char validFlag = inPack.range(255,248);
ap_uint<8> score = inPack.range(263,256);
ap_int<24> m_10 = 0;
ap_int<24> m_01 = 0;
ap_uint<64> val = 0;
read_col_loop:
for(ap_uint<6> k = 0;k<31;k++)
{
#pragma HLS UNROLL
#pragma HLS LOOP_TRIPCOUNT MAX=31
for(ap_uint<8> s = 0;s<31;s++)
{
#pragma HLS UNROLL
if(k!=30)
src_buf[s][k] = src_buf[s][k+1];
else
src_buf[s][30] = (unsigned char)temp.range(s*8+7,s*8);
}
}
if(validFlag == 127)
{
momentPackStream.write(val);
}
else if(validFlag == 255 )
{
for(ap_int<8> i = 0;i<31;i++)
{
#pragma HLS PIPELINE
unsigned char vres0[32];
#pragma HLS ARRAY_PARTITION variable=vres0 complete dim=1
ap_uint<9> vres1[16];
#pragma HLS ARRAY_PARTITION variable=vres1 complete dim=1
ap_uint<10> vres2[8];
#pragma HLS ARRAY_PARTITION variable=vres2 complete dim=1
ap_uint<11> vres3[4];
#pragma HLS ARRAY_PARTITION variable=vres3 complete dim=1
ap_uint<12> vres4[2];
#pragma HLS ARRAY_PARTITION variable=vres4 complete dim=1
ap_uint<13> vres5;
ap_int<19> vres;
for(ap_uint<6>im = 0;im<32;im++)
{
if(im!=31)
vres0[im] = src_buf[i][im]&mask[i][im];
else
vres0[im] = 0;
}
for(ap_uint<6> i0 = 0;i0<16;i0++)
{
vres1[i0] = vres0[i0<<1]+vres0[(i0<<1)+1];
}
for(ap_uint<6> i1 = 0;i1<8;i1++)
{
vres2[i1] = vres1[i1<<1]+vres1[(i1<<1)+1];
}
for(ap_uint<6> i3 = 0;i3<4;i3++)
{
vres3[i3] = vres2[i3<<1]+vres2[(i3<<1)+1];
}
for(ap_uint<6> i4 = 0;i4<2;i4++)
{
vres4[i4] = vres3[i4<<1]+vres3[(i4<<1)+1];
}
vres5 = vres4[0]+vres4[1];
vres = vres5*(i-15);
m_01 += vres;
unsigned char ures0[32];
#pragma HLS ARRAY_PARTITION variable=ures0 complete dim=1
ap_uint<9> ures1[16];
#pragma HLS ARRAY_PARTITION variable=ures1 complete dim=1
ap_uint<10> ures2[8];
#pragma HLS ARRAY_PARTITION variable=ures2 complete dim=1
ap_uint<11> ures3[4];
#pragma HLS ARRAY_PARTITION variable=ures3 complete dim=1
ap_uint<12> ures4[2];
#pragma HLS ARRAY_PARTITION variable=ures4 complete dim=1
ap_uint<13> ures5;
ap_int<19> ures;
for(ap_uint<6> im = 0;im<32;im++)
{
if(im!=31)
ures0[im] = src_buf[im][i]&mask[im][i];
else
ures0[im] = 0;
}
for(ap_uint<6> i0 = 0;i0<16;i0++)
{
ures1[i0] = ures0[i0<<1]+ures0[(i0<<1)+1];
}
for(ap_uint<6> i1 = 0;i1<8;i1++)
{
ures2[i1] = ures1[i1<<1]+ures1[(i1<<1)+1];
}
for(ap_uint<6> i3 = 0;i3<4;i3++)
{
ures3[i3] = ures2[i3<<1]+ures2[(i3<<1)+1];
}
for(ap_uint<6> i4 = 0;i4<2;i4++)
{
ures4[i4] = ures3[i4<<1]+ures3[(i4<<1)+1];
}
ures5 = ures4[0]+ures4[1];
ures = ures5*(i-15);
m_10 += ures;
}
val.range(23,0) = m_10;
val.range(47,24) = m_01;
val.range(55,48) = validFlag;
val.range(63,56) = score;
momentPackStream.write(val);
}
}
}/
代码解析:
HLS指令逻辑解析
#pragma HLS ARRAY_PARTITION variable=mask complete dim=1/2
将mask数组在第 1、2 维度完全分块(拆解为独立寄存器),避免硬件访问数组时的端口冲突,支持并行读写。
/
#pragma HLS ARRAY_PARTITION variable=src_buf complete dim=1/2
对 31x31 的像素缓存src_buf做同样的完全分块,确保 31x31=961 个像素可被并行访问。
/
#pragma HLS UNROLL
展开循环(如read_col_loop的内层循环),将循环迭代转换为并行硬件逻辑,减少计算延迟。
/
#pragma HLS PIPELINE
对循环(如计算矩的外层循环)进行流水线化,允许上一次迭代未完成时启动下一次迭代,提高数据处理速率(理想情况下每个时钟周期处理一个数据)。
/
#pragma HLS LOOP_TRIPCOUNT MAX=31
告诉 HLS 工具循环最大迭代次数为 31,帮助工具优化硬件资源分配。该参数对硬件资源调配影响很大,后期可以通过调整这里参数优化速度。
/
输入输出流
datapackStreamIn 输入流,每个元素是 264 位的ap_uint<264>,包含
248 位像素数据(temp,31 个 8 位像素,31×8=248)
8 位有效标志(validFlag,248~255 位)
8 位分数(score,256~263 位,可能是角点响应值等)
src_buf[31][31] 输出流,每个元素是 64 位的ap_uint<64>,包含计算结果(见后文打包逻辑)
mask[31][31] 31x31 的掩码(前文提到的二值掩码),通过&操作筛选窗口内的有效像素(仅保留mask为 255 的位置像素)
/
矩计算变量
m_10/m_01 31x31 窗口的一阶矩(m₁₀对应 x 方向,m₀₁对应 y 方向),类型为 24 位有符号整数(ap_int<24>),用于存储累加结果
核心逻辑实现
/
滑动窗口更新
31x31 窗口的一阶矩(m₁₀对应 x 方向,m₀₁对应 y 方向),类型为 24 位有符号整数
for(ap_uint<6> k = 0;k<31;k++){
for(ap_uint<8> s = 0;s<31;s++){
if(k!=30)
src_buf[s][k] = src_buf[s][k+1]; // 左移一列(丢弃第0列,保留1~30列)
else
src_buf[s][30] = (unsigned char)temp.range(s*8+7,s*8); // 第30列更新为新输入像素
}}每次从输入流读取一个数据包(含 31 个像素),通过左移将src_buf的列依次左移,最后一列(第 30 列)填充新像素,形成 “窗口向右滑动” 的效果。
31x31 的窗口大小与掩码匹配,确保后续计算的像素范围与掩码有效区域一致。
/
基于ValidFlag 的分支处理
validFlag是输入数据的 “控制信号”,用于标记当前数据的状态
当validFlag == 127:直接输出空值(val=0),可能表示当前窗口无效(如图像边缘,窗口未完全填充)。
当validFlag == 255:窗口有效,执行矩计算(核心逻辑)
/
一阶矩m01 m10计算
这部分是函数的核心,通过多级并行累加实现高效计算,分为m₀₁(y 方向)和m₁₀(x 方向)两部分,逻辑对称:
以m₀₁计算为例(vres系列变量)
// 步骤1:应用掩码筛选有效像素
for(ap_uint<6> im = 0;im<32;im++){
if(im!=31)
vres0[im] = src_buf[i][im] & mask[i][im]; // 仅保留掩码为255的像素
else
vres0[im] = 0; // 边界补0
}
// 步骤2:多级累加(树状并行求和)
vres1[i0] = vres0[2i0] + vres0[2i0+1]; // 32→16
vres2[i1] = vres1[2i1] + vres1[2i1+1]; // 16→8
vres3[i3] = vres2[2i3] + vres2[2i3+1]; // 8→4
vres4[i4] = vres3[2i4] + vres3[2i4+1]; // 4→2
vres5 = vres4[0] + vres4[1]; // 2→1(得到第i行的有效像素总和)
// 步骤3:计算矩并累加
vres = vres5 * (i - 15); // (i-15)是y方向中心偏移(窗口中心在i=15)
m_01 += vres; // 累加得到整个窗口的m₀₁掩码作用:通过& mask[i][im]仅保留掩码有效区域(255)的像素,排除无效区域(0)的干扰。
多级累加:将 32 个元素通过 5 级加法树(32→16→8→4→2→1)并行求和,比单纯循环累加的延迟更低(硬件中加法器可并行工作)
中心偏移:i-15将坐标原点移到 31x31 窗口的中心(31 的中点是 15),计算的是中心矩(而非原点矩),更能反映窗口内像素的分布重心。
m₁₀的计算逻辑完全对称(ures系列变量),只是将行和列的索引互换(src_buf[im][i] & mask[im][i]),最终得到 x 方向的中心矩。
/
计算结果打包输出
val.range(23,0) = m_10; // 低24位:m₁₀(x方向矩)
val.range(47,24) = m_01; // 中24位:m₀₀(y方向矩)
val.range(55,48) = validFlag; // 高8位:有效标志(255)
val.range(63,56) = score; // 最高8位:分数(如角点响应值)
补充
该文章是写word版本的转换成博客文章的,格式和颜色略有偏差,如果看得不舒服可以访问下面链接获取:
【金山文档 | WPS云文档】 FAST角点检测 HLS代码解析
ORB-SLAM3硬件加速项目系列
点击文章下方标签获取整个系列更新文章!