

引言
阅读UG1399的时候,我们会看到它罗列了三种编程范例。
而这个正是我们更好去理解高级编程语言和FPGA编程之间的区别。
Xilinx的HLS编程中,它主要有三大范例:生产者使用者范例、串流数据范例、流水线范例,我会在下文中详细罗列出UG1399对这部分的介绍,如果你已经看过了可以跳过这一部分。原文写得虽然逻辑严谨,但是内容冗长不易理解。
我在网上搜索了许多关于HLS编程的三大范例的,网上大多都是原文照搬,特别不负责任!于是我才想要展开这番外篇的内容。
这个番外篇是针对教程的理论补充,以便于大家的理解,不看的话也能完成教程里面的实验。
原文截图
生产者使用者

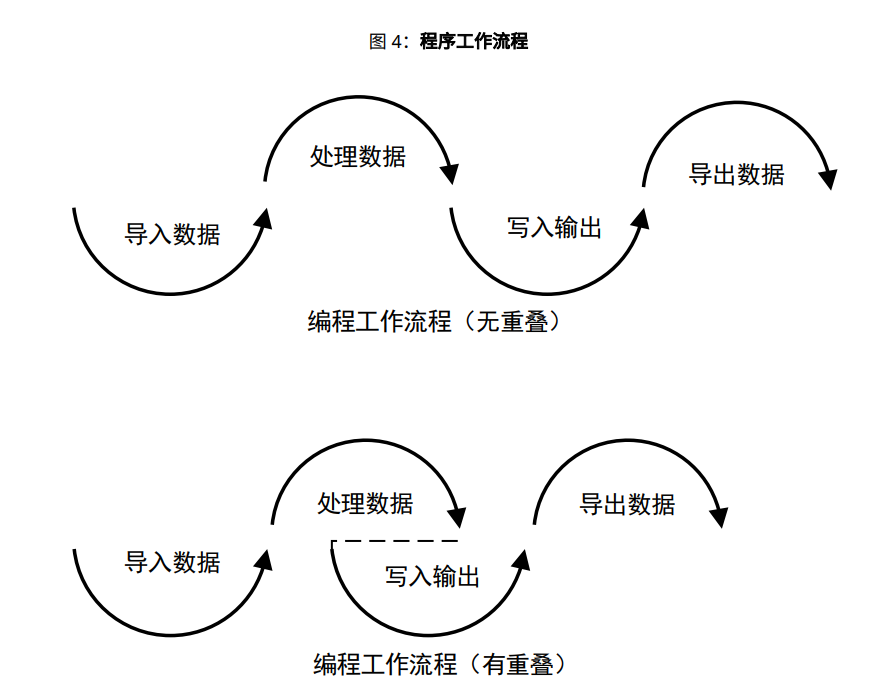


串流数据范例

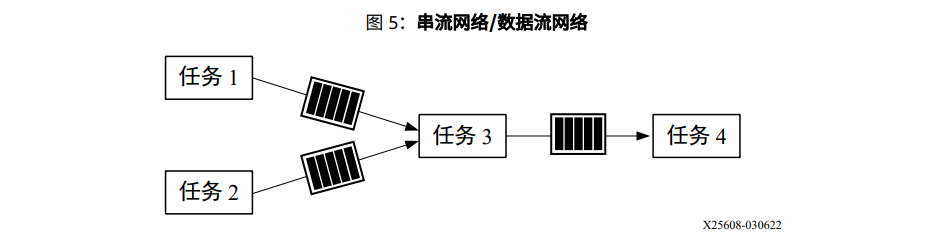

流水线范例

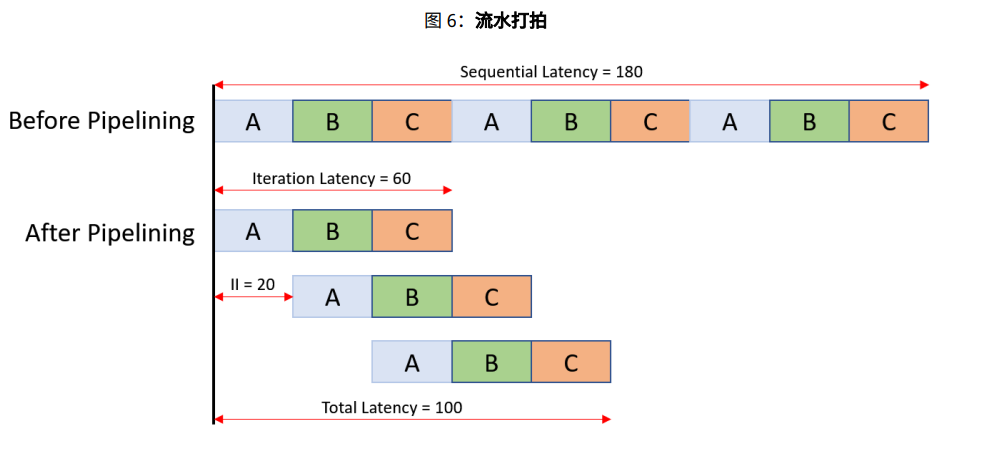

生产者使用者范例
我们先抛弃掉复杂的概念,回归到生活中来,
场景:
一个工厂生产手机屏幕,分为两个步骤:
<1>生产者:切割玻璃(数据生成)。
<2>使用者:打磨玻璃(数据处理)。
<3>缓冲区:中间仓库(存储切割后的玻璃,等待打磨)。
问题:
如果生产者和使用者顺序执行,效率很低。例如:
- 切割完一片玻璃后,必须等打磨完成,才能开始下一片切割。
- 总耗时 = 切割时间 + 打磨时间 × 片数。
解决方案:
用 生产者-使用者模型,让两者并行工作:
<1>生产者切割玻璃后,直接放入中间仓库。
<2>使用者从仓库取玻璃打磨,无需等待生产者。
<3>两者独立运行,效率翻倍。
简单理解以后我们来通过代码的范例理解一串C语言的代码是如何表述这个场景,然后转化成HLS的开发逻辑的。
C语言实现(传统逻辑)
场景
% 生产者(CutGlass)切割玻璃,放入缓冲区。
% 消费者(Polish)从缓冲区取玻璃进行打磨。
% 缓冲区用数组模拟。
代码:
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 10
#define NUM_GLASSES 20
void CutGlass(int buffer[BUFFER_SIZE], int *write_index) {
for (int i = 0; i < NUM_GLASSES; i++) {
while (*write_index == BUFFER_SIZE) {} // 等待缓冲区空
buffer[*write_index] = i; // 切割玻璃
*write_index += 1;
printf("Produced glass %d\n", i);
}
}
void Polish(int buffer[BUFFER_SIZE], int *read_index) {
for (int i = 0; i < NUM_GLASSES; i++) {
while (*read_index == 0) {} // 等待缓冲区有数据
int glass = buffer[*read_index]; // 取出玻璃
*read_index += 1;
printf("Polished glass %d\n", glass);
}
}
int main() {
int buffer[BUFFER_SIZE];
int write_index = 0, read_index = 0;
// 顺序执行:先切割,再打磨
CutGlass(buffer, &write_index);
Polish(buffer, &read_index);
return 0;
}通过阅读代码我们可以发现出问题:
顺序执行:生产者必须等全部切割完成,消费者才能开始打磨,生产者和消费者无法同时运行。
缓冲区依赖:使用普通数组,需手动管理读/写索引,效率低。
修改后的HLS代码:
#include <hls_stream.h>
// 定义数据类型(假设每个玻璃数据为整数)
typedef int Glass;
// 生产者模块
void CutGlass(hls::stream<Glass> &output) {
for (int i = 0; i < 20; i++) {
output.write(i); // 将切割后的玻璃写入流
printf("Produced glass %d\n", i);
}
}
// 消费者模块
void Polish(hls::stream<Glass> &input) {
for (int i = 0; i < 20; i++) {
Glass glass = input.read(); // 从流中读取玻璃
printf("Polished glass %d\n", glass);
}
}
// 主函数(HLS入口)
void ScreenProduction() {
#pragma HLS DATAFLOW // 允许生产者和消费者并行运行
hls::stream<Glass> buffer; // 使用流代替数组
CutGlass(buffer); // 生产者
Polish(buffer); // 消费者hls::stream<T>
使用该函数声明它是一个硬件级 FIFO(先进先出)缓冲区。
内部会自动管理指针,不需要像C语言一样维护read 和 write指针。
#pragma HLS DATAFLOW
在HLS中,DATAFLOW 指令告诉工具:这两个模块可以独立运行,只要数据流满足。也就是这两个可以同时跑。
串流数据范例
场景:
快递公司运输包裹:
快递员:收集包裹(数据生成)。
中转站:暂存包裹(数据缓冲)。
运输车:将包裹送至目的地(数据处理)。
问题:
如果一次性加载所有包裹到中转站,内存占用高,效率低。
解决方案:
用 串流(Streaming):
快递员将包裹按顺序放入中转站(
hls::stream)。运输车按需从中转站取包裹,无需一次性加载全部数据。
“生产者使用者范例”中已经有提到过hls::stream的使用,本小节再举一个例子以便大家更好理解
C语言实现(传统逻辑)
场景:
快递员收集包裹(数据生成)。
运输车将包裹送至目的地(数据处理)。
用数组模拟缓冲区,手动管理读写索引。
代码:
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 10
#define NUM_PACKAGES 20
// 快递员收集包裹
void Courier(int buffer[BUFFER_SIZE], int *write_index) {
for (int i = 0; i < NUM_PACKAGES; i++) {
while (*write_index == BUFFER_SIZE) {} // 等待缓冲区空
buffer[*write_index] = i; // 存放包裹
*write_index += 1;
printf("Collected package %d\n", i);
}
}
// 运输车运输包裹
void Transport(int buffer[BUFFER_SIZE], int *read_index) {
for (int i = 0; i < NUM_PACKAGES; i++) {
while (*read_index == 0) {} // 等待缓冲区有数据
int package = buffer[*read_index]; // 取包裹
*read_index += 1;
printf("Transported package %d\n", package);
}
}
int main() {
int buffer[BUFFER_SIZE] = {0}; // 缓冲区
int write_index = 0, read_index = 0;
// 顺序执行:先收集包裹,再运输
Courier(buffer, &write_index);
Transport(buffer, &read_index);
return 0;
}这样写的话,顺序执行,十分依赖上一级是否有处理完。
修改后的HLS代码:
#include <hls_stream.h>
// 定义包裹数据类型
typedef int Package;
// 快递员模块
void Courier(hls::stream<Package> &output) {
for (int i = 0; i < 20; i++) {
output.write(i); // 放入包裹到流中
printf("Collected package %d\n", i);
}
}
// 运输车模块
void Transport(hls::stream<Package> &input) {
for (int i = 0; i < 20; i++) {
Package package = input.read(); // 从流中取包裹
printf("Transported package %d\n", package);
}
}
// 主函数(HLS入口)
void PackageTransport() {
#pragma HLS DATAFLOW // 允许快递员和运输车并行运行
hls::stream<Package> packageStream; // 使用流代替数组
Courier(packageStream); // 快递员模块
Transport(packageStream); // 运输车模块
}流水线范例
C语言实现(传统逻辑)
场景:
对图像的每个像素依次进行 加法、乘法 和 阈值处理 三个步骤。
顺序执行,无法并行。
代码:
#include <stdio.h>
#define IMG_SIZE 10
// 图像处理模块
void ImageProcessing(int input[IMG_SIZE], int output[IMG_SIZE]) {
for (int i = 0; i < IMG_SIZE; i++) {
int a = input[i] + 10; // 阶段1:加法
int b = a * 2; // 阶段2:乘法
int c = (b > 128) ? 255 : 0; // 阶段3:阈值处理
output[i] = c;
printf("Processed pixel %d\n", i);
}
}
int main() {
int input[IMG_SIZE] = {0, 10, 20, 30, 40, 50, 60, 70, 80, 90};
int output[IMG_SIZE] = {0};
ImageProcessing(input, output);
return 0;
}修改后的HLS代码:
#include <hls_stream.h>
// 定义像素数据类型
typedef int Pixel;
// 流水线模块(加法、乘法、阈值处理)
void ImagePipeline(hls::stream<Pixel> &input, hls::stream<Pixel> &output) {
#pragma HLS PIPELINE II=1 // 启用流水线,每周期启动一个新像素
Pixel a, b, c;
while (!input.empty()) {
a = input.read(); // 阶段1:加法
b = a * 2; // 阶段2:乘法
c = (b > 128) ? 255 : 0; // 阶段3:阈值处理
output.write(c); // 输出结果
printf("Processed pixel\n");
}
}
// 主函数(HLS入口)
void ImageProcessing() {
hls::stream<Pixel> inputStream, outputStream;
// 填充输入流
for (int i = 0; i < 10; i++) {
inputStream.write(i * 10); // 模拟输入数据
}
ImagePipeline(inputStream, outputStream); // 调用流水线模块
}#pragma HLS PIPELINE II=1
该指令将内部分为多个流水线,每周期启动一个新像素。
在传统C中,每次循环必须等所有步骤完成才能开始下一次循环。在HLS中,PIPELINE 指令告诉工具:将循环体拆分为多级流水线,每级独立运行。
总结
实际上我们在上面的例子也会看得出来,各个范例并不是对立关系。他们之间可以相互结合以求最大处理速率。
同时我们也能在C语言和HLS编程逻辑的对比中发现,FPGA的并行处理能力十分强大,传统的处理逻辑依托于CPU去一条条处理指令,尽管有系统去最大化的利用CPU的资源,在这种处理简单逻辑的运算中,一定数量的FPGA运算单元是能超过CPU 的效率的。本质上你的电脑需要GPU去处理图像的原因也正是如此,术业有专攻。而FPGA正是由于它的通用性,才能在运算性能不断升级的时代中依旧保有一席之地。
三者如何相互结合,如何在效率和资源占用上进行取舍,是需要我们长期积累经验,才能在开发前期比较清晰地判断出资源和效率见的平衡点的,不过相信你在看完这一篇后,能够对HLS开发和C语言的异同有了更深的理解。文章中的代码或许有不成熟的地方,欢迎大家评论区指正!